A personal summary of "Designing Data-Intensive Applications"
David Reis|September 10, 2024 (2y ago)

This is my personal summary of Martin Kleppmann's "Designing Data-Intensive Applications". I cannot overstate how invaluable Martin's book has been in shaping my understanding of data-intensive applications and distributed systems. I want to emphasize that this summary is not intended to replace the book itself, but rather to serve as a collection of reminders, helping me (and you?) recall the complex concepts and nuances that Martin presents so clearly.
Foundations of Data Systems#
Reliable, Scalable and Maintainable Applications#
Reliability#
Systems work correctly, even when faults occur.
Types of faults:
- Hardware
- Software (bugs)
- Human
Fault-tolerance improves reliability.
Scalability#
Keeping performance good, even when load increases.
Tail latency - slowest % of requests.
In a scalable system, you can add processing capacity in order to remain reliable under high load.
Maintainability#
Making life better for the engineering and operations teams who work with the system.
Reduce complexity.
Make system easier to modify and adapt for new use cases.
Good operability means having good visibility into the system's health and effective ways to manage it.
Data Models and Query Languages#
Relational Model#
Relational. SQL.
Document Model#
Good for applications where data has a document-like structure. Shredding the document into multiple tables can be cumbersome and overly complicate the application code.
Bad support for joins, especially many-to-many.
Usually no schema enforced - however, your application most likely still assumes that data has a certain structure - the schema may be explicit (enforced on write) or implicit (handled on read).
Graph Model#
Good for applications where many-to-many relationships are very common.
Also usually no schema enforced.
Storage and Retrieval#
OLTP (Transaction Processing)#
Typically user facing, handling huge volumes of requests. Each query usually touches a small part of the database. Application requests records based on key, consults an index and returns. Disk seek time is often a bottleneck.
Log-structured storage (SSTables and LSM-Trees)
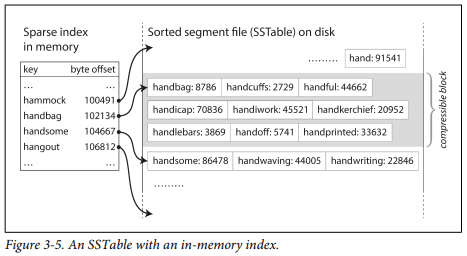
Consists of keeping a append-only log of key-value entries, and an index that maps (some or all) keys to it's location in the log (i.e. a byte offset). Only permits appending to files and deleting obsolete files, but never updates a file that has been written.
Logs are broken into sorted segments of a certain size, new writes go to the latest segment. The compaction process reduces disk usage by throwing away old keys in the segments, keeping only the most recent update for each key. Small segments are merged together. Segments are never modified after they have been written, so merge writes a new file. The compaction and merge process can be done in a background thread (no downtime).
Tombstones are used for deleting keys.
Sequential writes are fast (good for spinning disks especially), so writing new/updated entries is fast. Range queries can be fast since work is done to ensure that records are stored sequentially.
Each segment is sorted. This allows for a more efficient merge process. A sparse index and searching a key through a sequential range can be fast enough (or even no index - if keys and values are fixed size we can just binary search through the file).
The latest segment (where new, updated or tombstone entries are written) is kept in memory using sorted structures such as red-black trees or AVL trees. After reaching the threshold size, the segment is written to disk already in sorted order. An unsorted log can be kept for persistency sake.
Examples: LevelDB, RocksDB, Cassandra. Bigtable paper by Google introduced concepts. Lucene (full-text engine powers ElasticSearch and Solr. Term dictionary is a SSTable-like files where key is a word and value is list of IDs of documents that contain that word).
Bloom filters can be used to quickly know for sure that a key is not in a given segment.
Merge and compaction makes it so that a single write to the database ends up creating multiple writes in its lifespan. This is known as write amplification. It can also impact the application's performance, despite being a parallel process.
B-Trees
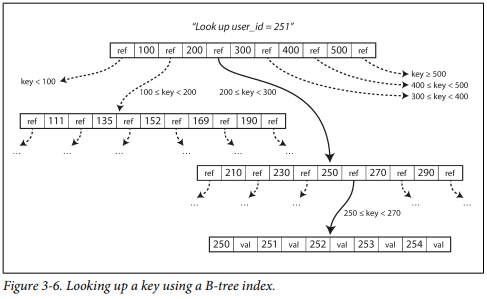
Balanced tree of pages. Balanced means that a B-tree with n keys always has a depth of O(log n). Branching factor is the number of references to child pages in a single page (in figure it is 6). Write operations are more costly, but no merge or compaction is necessary. A WAL log can be used for reliability. Concurrency involves locking branches of the tree. Pages can be positioned anywhere on the disk, making sequential reads more difficult.
OLAP (Analytics Processing)#
Primarily used for analytics, business analysis, not end users. Much lower volume of queries, but each request is usually much more demanding. Many millions of records are requested in a single query. Disk bandwidth is often the bottleneck. Column-oriented storage is a popular solution. Materialized views are an option to cache some frequently used intermediate representation of the data.
Encoding and Evolution#
Encoding plays a big role in an application's evolvability.
During rolling upgrades, we must assume that different nodes are running different versions of our application's code. Thus, it is important that all data flowing around the system is encoded in a way that provides backward compatibility (new code can read old data) and forward compatibility (old code an read new data).
Programming language-specific formats#
🗑️ (for 99% of use-cases)
Textual formats#
JSON, XML, CSV.
Vague about datatypes - numbers and binary strings can differ from library to library.
Optional schema enforcement. Must include field names on every entity. The field name is tied to the encoding. Backward and forward compatibility require gymnastics.
Binary formats#
Protobuf, Avro.
Allow for compact and efficient encoding with clearly defined forward and backward compatibility semantics.
Dataflow#
There are different concerns regarding encoding when dealing with databases, web services, and RPC.
Databases
Data outlives code. Data may be stored that the writer application is long gone. Needs schema evolution to hande that, and care so that fields are not lost in the deserialization / serialization process.
Web Services
A key design goal of a service-oriented/microservices architecture is to make the application easier to change and maintain by making services independently deployable and evolvable.
Thrift, gRPC (Protocol Buffers), and Avro RPC can be evolved according to the compatibility rules of the respective encoding format.
RESTful APIs most commonly use JSON (without a formally specified schema) for responses, and JSON or URI-encoded/form-encoded request parameters for requests. Adding optional request parameters and adding new fields to response objects are usually considered changes that maintain compatibility.
Interested in blog posts like this one?
Receive an email when I publish new posts.
Distributed Data#
Replication#
Replication can serve several purposes:
- High Availability
- Keeping the system running, even if one machine goes down.
- Disconnected operation
- Allowing an application to continue working when there is a network partition.
- Latency
- Place data geographically close to consumers.
- Scalability
- Able to handle higher volume of reads than a single machine could, by performing reads on replicas.
And different approaches can be used:
- Single-leader replication
- Client sends all writes to the leader, which sends a stream of data change events to followers. Reads can be performed on any replica, but if replication is async then follower reads might be stale.
- Easy to understand, no conflict resolution needed.
- Multi-leader replication
- Clients send each write to one of several leader nodes. Leaders share streams of data change events to each other and any follower nodes.
- Leaderless replication
- Clients send each write to several nodes, and read from several nodes in parallel in order to detect and correct nodes with stale data. A consensus is necessary and important.
Conflicts can occur in multi-leader and leaderless models. One example of a resolution strategy is last-write-wins. CRDTs may be useful in this domain.
Asynchronous replication (propagation of changes from one replica to all other replicas) can be fast, but stale data can be read. What happens if replication gets massively delayed? If a leader fails and an async replica gets promoted, recently committed data may be lost.
Different replication lag guarantees can be worked into the system:
- Read-after-write consistency
- Read your own writes.
- Monotonic reads
- After users have seen the data at one point, they shouldn't later see the data from some earlier point in time.
- Consistent prefix reads
- Users should see data in a state that makes causal sense (e.g. a group messaging app needs to show messages in order).
Partitioning#
Partitioning is necessary when there is so much data that storing or processing it on a single machine is no longer feasible.
Goal is to spread the data and processing load evenly across multiple machines, avoiding hotspots.
Two main approaches to partitioning, key range and hash partitioning.
Key range partitioning#
Keys are sorted and a partition owns all the keys from some minimum up to some maximum. Efficient range queries, but risk of hotspots. Partitions are rebalanced dynamically by splitting the range into two subranges when a partition gets too big.
Hash partitioning#
Hash function applied to each key, a partition owns a range of hashes. Destroys ordering of keys, but may distribute load more evenly. Common to create a fixed number of partitions in advance, assign several partitions to each node, and move entire partitions from one node to another when nodes are added or removed.
Node = hash mod N is a mistake - rebalancing involves moving around loads of data. Fixed partition count where partition_count > node_count is a much better solution.
If there are still hotspots, one can add a random prefix (or suffix) to the key, and one particularly hot key would be distributed into multiple partitions. This has obvious drawbacks.
Hybrid approaches are also possible, for example with a compound key: using one part of the key to identify the partition and another part for the sort order.
Secondary indexes#
Secondary indexes also need to be partitioned. Two methods for that:
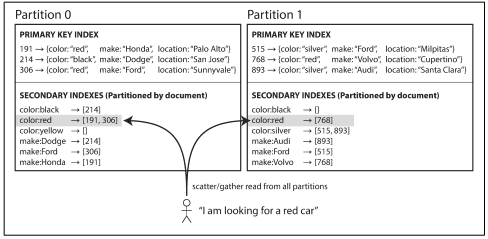
- Document-partitioned indexes (local indexes): The secondary indexes are stored in the same partition as the primary key and value. Only a single partition needs to be updated on write, but a read will be scattered.
- Term-partitioned indexes (global indexes): The secondary indexes are partitioned, using the indexed values. A read can be served from a single partition, but writes will need to update several partitions.
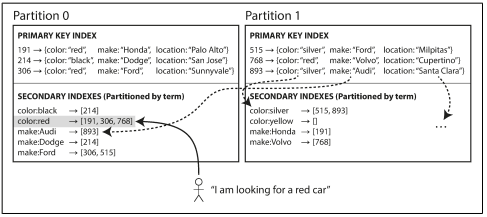
Routing queries to the appropriate partition is a problem of service discovery, which has many solutions, one of which is a strongly consistent data store such as Apache ZooKeeper.
Transactions#
ACID#
- Atomicity: A transaction cannot complete partially. The system is either in a state where the transaction didn't run at all, or the transaction was successfully completed.
- Consistency: The system is always in a state where data constraints are not broken. It's up to the application to create these constraints, so this is a weird one.
- Isolation: Concurrently executing transactions do not interact with each other in any way. The database ensures that when the transactions have committed, the result is the same as if they had run serially. (Isolation in the real-world is a spectrum. See Weak Isolation Levels.)
- Durability: Once a transaction has committed successfully, any data it has written will not be lost, even if there is a hardware fault or database crash. Typically means that data has been written to nonvolatile storage. May also involve a WAL. Can also mean replication to other nodes.
Weak Isolation Problems#
Dirty Read
Seeing data that has not been committed yet.
Dirty Write
Writing data over an entry that has not been committed yet.

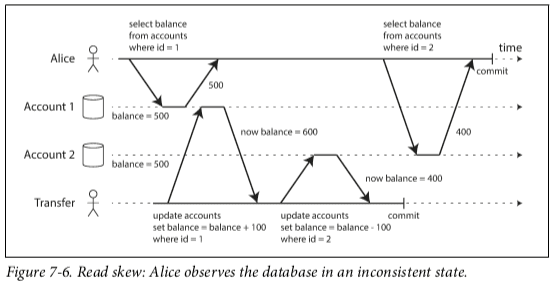
Read Skew (or Nonrepeatable Read)
A transaction reads a value that has an uncommitted update pending by other transaction, sees the old value, then reads another value after the other transaction has committed. If the transaction was repeated right after, it would yield different values (hence nonrepeatable read).
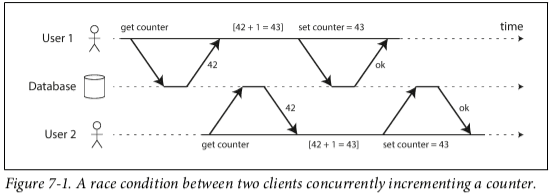
Lost Update (special case of Write Skew)
One transaction increments a value by 1, another concurrent transaction does the same, because of snapshot isolation only one of the increments gets persisted.
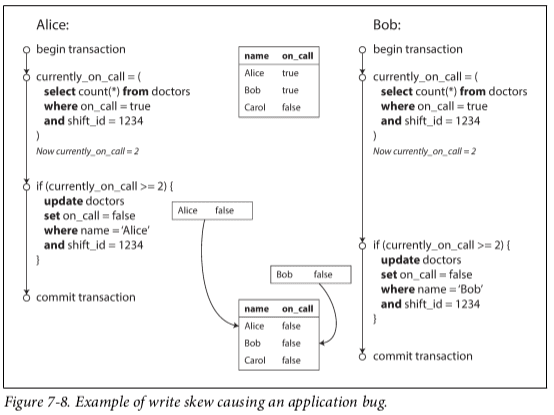
Write Skew
A read is made to determine if a write will be made. It's a generalization of Lost Update because here we're not necessarily writing to the same row, making it harder to detect automatically. This effect, where a UPDATE or DELETE is done conditionally by a SELECT that has been affected by a concurrent transaction, is called a phantom read.
Weak Isolation Levels#
Read Committed
Prevents dirty reads and dirty writes.
- When reading from the database, you will only see data that has been committed (no dirty reads).
- When writing to the database, you will only overwrite data that has been committed (no dirty writes).
Very popular isolation level, it's the default level for many databases including PostgreSQL.
Implements 1. by returning old values to reads that have non-committed updates and implements 2. using row-locks. Row-locks could be used to prevent 1. but then reads would be blocked by writes.
Snapshot Isolation / Repeatable Read
Prevents dirty reads, dirty writes and read skew.
It can also prevent lost updates (automatically in PostgreSQL, Oracle and SQL Server, with a FOR UPDATE lock on the read on MySQL and others).
It can also prevent write skew (with a FOR UPDATE lock on the read on all DBs).
Each transaction reads from a consistent snapshot of the database, taken at the start of the transaction.
Particularly useful to ensure consistent data on backups, long-running (analytics) queries and integrity checks.
Like read committed, locks are used to prevent dirty writes.
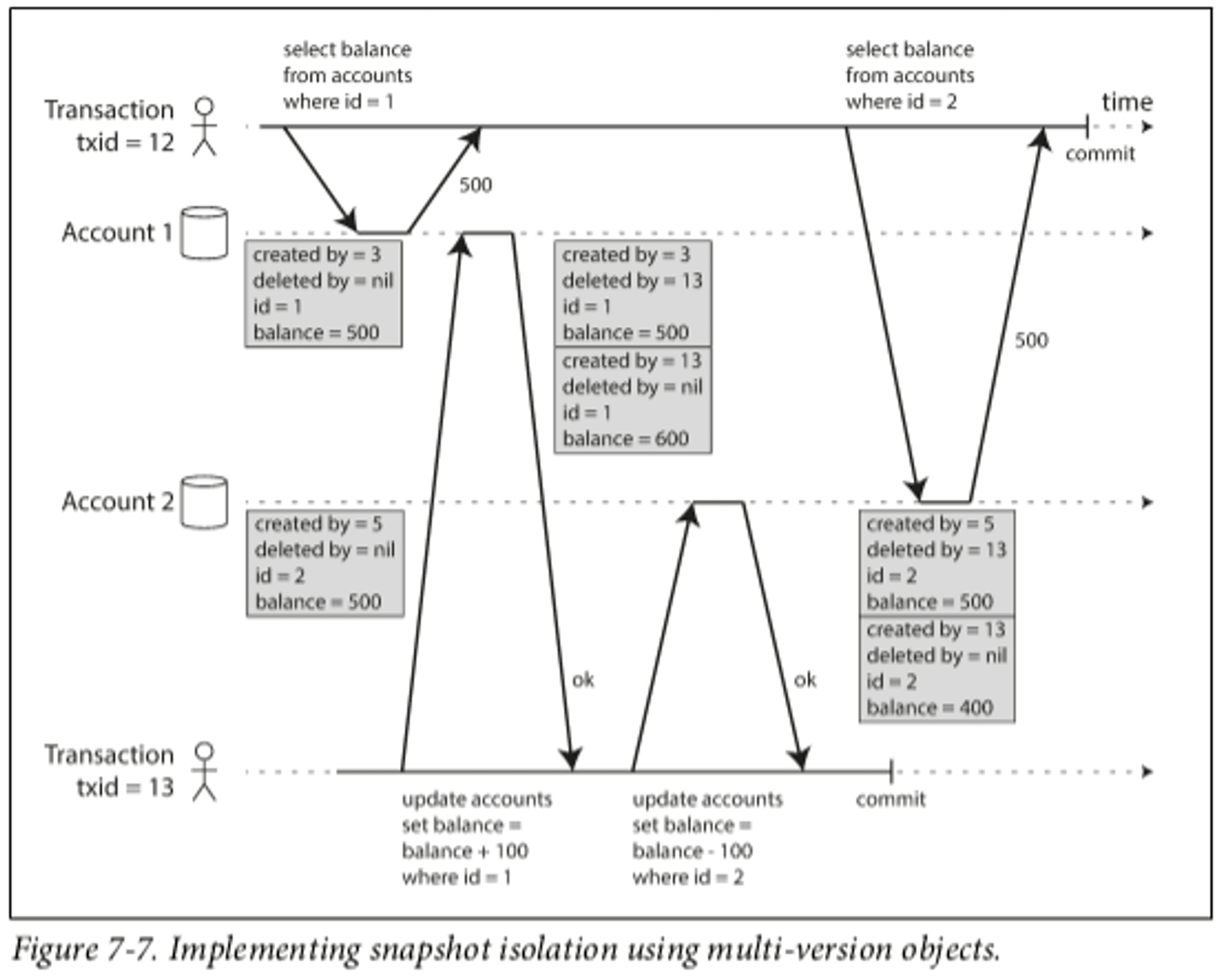
To prevent dirty reads and read skew, Multi-Version Concurrency Control (MVCC) is used. Consists in keeping multiple versions of the database, which is needed since each transaction needs to see a snapshot that includes all (and just) the committed transactions at the start of the transaction. When a transaction is started, it is given a unique, monotonically increasing transaction ID. Whenever a transaction writes anything to the database, the data it writes is tagged with the transaction ID of the writer.
So this is basically about what writes are visible to you as a reading transaction. The ones that are visible to you are all the values written by a transaction ID lower than your own and wasn't already running when your transaction started.
Serializable
Strongest isolation level. Protects against all the weak isolation problems. Even though transactions may execute in parallel, the end result is the same as if they had executed one at a time. There are multiple ways to implement it:
- Actual Serial Execution: Slow, not scalable, not partitionable. Only suitable for small and fast transactions. Dataset must fit into memory, otherwise a transaction could be too slow. Low write throughput.
- Two-Phase Locking: Writers don't just block writers, they also block readers. Used by MySQL and SQL Server. Uses shared locks (acquired by readers) and exclusive locks (acquired by writers). Readers don't block each other, but writers block everyone else. Prone to deadlocks. Still bad performance due to excessive locking, particularly with long transactions.
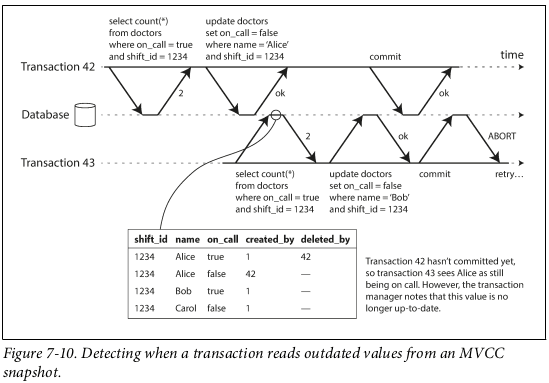
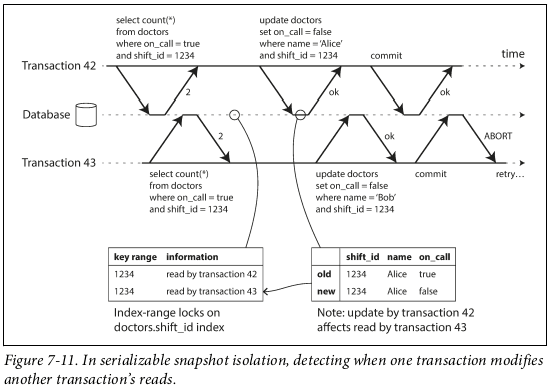
- Serializable Snapshot Isolation: Optimistic algorithm. Runs transactions with snapshot isolation and detects whether conflicts have happened when trying to commit. If conflicts have happened, transaction is aborted. Aborts transaction at commit when a stale MVCC read happens (we read a value that has since been changed by a committed transaction). Aborts transaction at commit when we have written a value that has affected a prior read (a read that happened after our transaction started but committed before us). Performance depends on how many transactions have to be cancelled due to conflicts.
The Trouble with Distributed Systems#
Timeouts are the only sure way of detecting faults and are vital to ensuring the guarantees offered by distributed systems.
There are two types of physical clocks, time-of-day and monotonic.
Time-of-day clocks#
Returns the current date and time. Is usually synchronized with NTP (Network Time Protocol) but there are other protocols. Usually have less resolution than monotonic clocks. Since they may drift (clock skew), when they are synchronized via NTP they may go backwards in value.
Monotonic clocks#
Return an integer value that is meaningless by itself but is guaranteed to be monotonically increasing. Reset to 0 on system reboot. Can be used to calculate durations, by subtracting one value from another. Lack synchronization since one computer's current monotonic clock value is meaningless to any other computer.
When ordering events, it's often best to use a logical clock instead of one of the previously mentioned physical clocks. A logical clock is simply based on incrementing counters. It's guaranteed to be monotonically increasing (although collisions may happen) and are meaningful to all machines in the system.
Google's TrueTime API in Spanner tries to make use of physical clocks by giving them an interval, [earliest_possible_timestamp, latest_possible_timestamp].
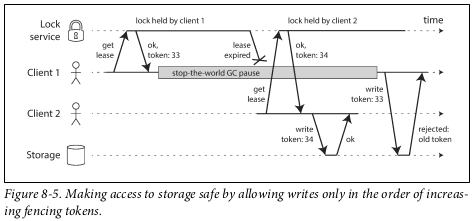
A process may pause for a substantial amount of time at any point in its execution (perhaps due to a stop-the-world garbage collector), be declared dead by other nodes, and then come back to life again without realizing that it was paused.
To fix that, one may use fencing tokens, which give one node access to a resource for a limited period of time.
Consistency and Consensus#
Linearizability#
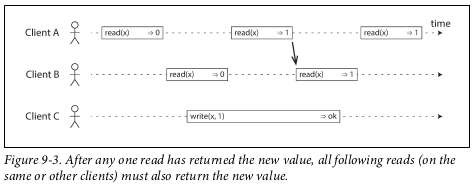
In a linearizable system, as soon as one client successfully completes a write, all clients reading from the database must be able to see the value just written. It should create the illusion that there is a single copy of the data. In other words, linearizability is a recency guarantee.
-
Linearizability vs Serializability
Linearizability is Needed but Serializability Isn't#
Example: Distributed Key-Value Store with Real-Time Updates
Consider a distributed key-value store used for maintaining the state of a real-time leaderboard in a multiplayer game. Players' scores are frequently updated, and the leaderboard needs to reflect these updates almost instantaneously.
-
Why Linearizability?
Linearizability ensures that once a player's score is updated, any subsequent read operation will reflect this update immediately. This guarantees that players see the most recent scores without any delay, maintaining a consistent and up-to-date view.
-
Why Not Serializability?
Serializability, which ensures that transactions appear to execute in some serial order, is not strictly necessary here. The operations on the leaderboard are simple updates and reads, and there is no need to group multiple operations into a transaction. The primary concern is the real-time reflection of individual updates, not the isolation of complex transactions.
Serializability is Needed but Linearizability Isn't#
Example: Banking System with Batch Transactions
Consider a banking system where end-of-day processing involves applying a batch of transactions to update account balances. These transactions can include deposits, withdrawals, and transfers between accounts.
-
Why Serializability?
Serializability ensures that the batch of transactions is applied in such a way that the end result is consistent with some serial order of execution. This is crucial for maintaining the integrity of account balances and ensuring that operations like transfers are correctly applied without conflicts.
-
Why Not Linearizability?
Linearizability, which ensures immediate visibility of operations, is not essential in this context. The batch processing can tolerate some delay in the visibility of updates as long as the final state is consistent and correct according to a serial order. The focus is on the atomicity and isolation of the batch transactions rather than their immediate effect.
Both Linearizability and Serializability are Needed#
Example: Online Shopping Cart System
Consider an online shopping cart system where users can add items to their cart, view the cart, and proceed to checkout. The system also involves inventory management to ensure items are available.
-
Why Linearizability?
Linearizability is needed to ensure that when a user adds an item to their cart, the item is immediately visible in their cart. This immediate reflection is crucial for user experience and for ensuring that users do not add the same item multiple times due to visibility delays.
-
Why Serializability?
Serializability is needed to ensure that the sequence of operations involving the cart and inventory is consistent. For example, when a user proceeds to checkout, the system needs to ensure that the items are still available and that the cart's state is consistent with the inventory. This requires transactions involving multiple operations (e.g., deducting items from inventory and creating an order) to be serializable to avoid race conditions and ensure data integrity.
In summary:
- Linearizability is needed for real-time visibility and immediate reflection of updates.
- Serializability is needed for the consistency and isolation of complex transactions.
- Both are needed when immediate visibility and transactional consistency are crucial for the application's correctness and user experience.
A database may provide both serializability and linearizability (aka strict serializability). If serializability is based on Two-Phase Locking or Actual Serial Execution then it is also linearizable. However, Serializable Snapshot Isolation is not linearizable, since it makes reads from a consistent snapshot to avoid lock contention between readers and writers. By design, this makes it so that a transaction may read an older value.
-
Linearizability is useful for:
Locking and leader Election - There must be only one leader, not several. Coordination services like ZooKeeper and etcd are often used for this purpose.
Constraints and uniqueness guarantees - Similar to acquiring a lock, if only one user can have a certain username, there has to be linearizability - after one user acquires the username, all others have to see that.
Cross-channel timing dependencies - In the example below, if after steps 2 there is no linearizability guarantee, then the image may not yet exist or be stale on step 5.
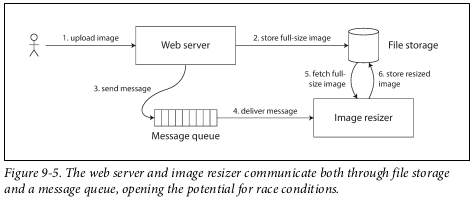
Single-leader replication with synchronous replication to read-only replicas has the potential to be linearizable, although it may not be, for example, if snapshot isolation is used.
Consensus algorithms, which bear a resemblance to single-leader systems, are linearizable, that is how Apache ZooKeeper and etcd work.
Multi-leader and leaderless replication are not linearizable.
CAP Theorem#
Consistent or Available when network Partitioned. If consistent, then system may not be available until the network partition is resolved. If available, then system may not be fully linearizable especially when network partitioned.
Ordering Guarantees#
Causal Order (Causality) - If a system obeys the ordering imposed by causality, we say that it is causally consistent. For example, snapshot isolation provides causal consistency: when you read from the database, and you see some piece of data, then you must also be able to see any data that causally precedes it. Git is a causal order system, hence the need to merge and resolve conflicts between two concurrent branches.
Total Order (Linearizability) - A total order allows any two elements to be compared. In a linearizable system, we have a total order of operations: if the system behaves as if there is only a single copy of the data, and every operation is atomic, this means that for any two operations we can always say which one happened first.
Linearizability is stronger than causal consistency, but typically more expensive.
Sequence numbers consist of using logical timestamps and are a good way to provide total order - any events A and B can be ordered by their timestamp in a way that is consistent with causality, and concurrent operations are also ordered, although arbitrarily. Nevertheless, that is considered total order.
If there isn't a single leader, it's harder to generate sequence numbers. You need to use Lamport timestamps. The key idea about Lamport timestamps, which makes them consistent with causality, is the following: every node and every client keeps track of the maximum counter value it has seen so far, and includes that maximum on every request. When a node receives a request or response with a maximum counter value greater than its own counter value, it immediately increases its own counter to that maximum.
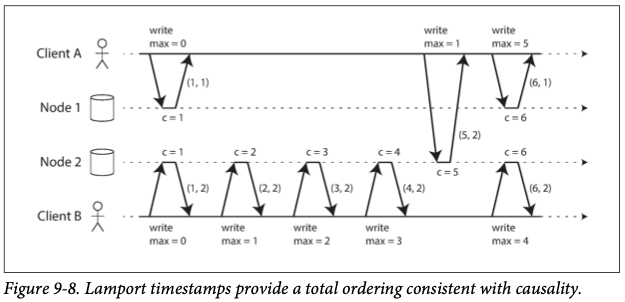
Note that total order is not sufficient to implement constraints like a uniqueness constraint for usernames, as total order may be eventual and not strong. So, just using Lamport timestamps, you wouldn't know when the order is finalized.
Total Order Broadcast#
Consists in two safety properties:
- Reliable delivery: No messages are lost. If a message is delivered to one node, it is delivered to all nodes.
- Totally ordered delivery: Messages are delivered to every node in the same order.
Even in the presence of a fault, these properties must be satisfied. (E.g. retrying if message failed).
ZooKeeper and etcd implement total order broadcast, so can be used as bricks to build a more complex system with strong guarantees.
If you have a system with total order broadcast, you can build linearizable storage on top of it with the following operations:
- Append a message to the log, tentatively indicating the username you want to claim.
- Read the log, and wait for the message you appended to be delivered back to you.
- Check for any messages claiming the username that you want. One of the following happens.
- If the first message for your desired username is your own message, then you are successful: you can commit the username claim (perhaps by appending another message to the log) and acknowledge it to the client.
- If the first message for your desired username is from another user, you abort the operation.
The previous is a linearizable write. To do a linearizable read, you can do one of the following:
- Append a message to the total order broadcast log, and then read all the messages until your own message is delivered back to you. That message is the point in time when the read happened, and you're guaranteed to be seeing all the writes that have previously happened. (Quorum read in etcd)
- If you can fetch the position of the latest log message in a linearizable way, query that position and wait until all entries up to that position are delivered to you. (ZooKeeper's sync() operation)
- Read from a replica that is synchronously updated on writes.
You can also implement total order broadcast with linearizable storage. For every message you want to send through total order broadcast, you increment-and-get the linearizable integer, and then attach the value you got from the register as a sequence number to the message. You can then send the message to all nodes (resending any lost messages), and the recipients will deliver the messages consecutively by sequence number.
Distributed Transactions#
In practice, distributed transactions should be avoided if possible.
Two-phase commit
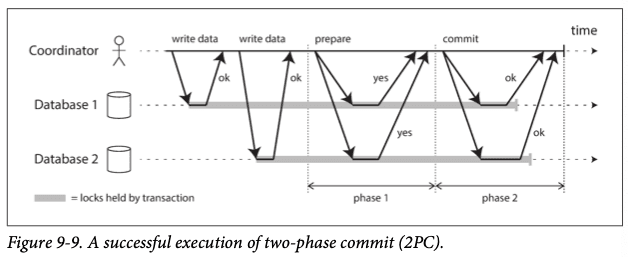
Points of no return:
- When a participant votes “yes”, it promises that it will definitely be able to commit.
- Once the coordinator decides to commit or abort, that decision is irrevocable.
2PC can become stuck - if a coordinator fails the nodes don't know how to proceed. Locks may be held indefinitely in each of the nodes.
3PC resolves this issue but assumes a network with bounded delay, which is most often not realistic.
- Database-internal distributed transactions: Can work quite well since they can be fully optimized for a particular technology.
- Heterogeneous distributed transactions: Most likely shit and should be avoided at all costs. XA transactions are a standard for implementing two-phase commit across heterogeneous technologies.
Fault-Tolerant Consensus#
One or more nodes may propose something, and the consensus algorithm decides on one of those values.
Properties:
- Uniform agreement - No two nodes decide differently.
- Integrity - No node decides twice.
- Validity - If a node decides value v, then v was proposed by some node.
- Termination - Every node that does not crash eventually decides some value.
Algorithms: Viewstamped replication (VSR), Paxos, Zab (Apache ZooKeeper) and Raft (etcd).
These algorithms decide on a sequence of values, making them total order broadcast algorithms. Total order broadcast is equivalent to repeated rounds of consensus, where each decision corresponds to one message delivery.
All algorithms define an epoch number and they guarantee that within each epoch, the leader is unique. Every time the leader is thought to be dead, a vote is started. Each election has an incremented epoch number, so epoch numbers are totally ordered and monotonically increasing. If there is a conflict between two potential leaders, the leader with the higher epoch prevails.
For a leader to confirm that itself is still the leader, it collects votes from a quorum (most of the times, a majority). So there are two rounds of voting, once to choose a leader, and a second to vote on a leader's proposal.
Comparing to 2PC, here the leader is elected as opposed to the coordinator, and a majority of nodes is enough to go through with an action. These consensus algorithms are, therefore, correct and fault tolerant in the event of a leader crash.
Consensus also has some limitations, it can be slow since it requires some synchronous communication between nodes, network problem can lead to high latency or even timeouts which make the algorithms unproductive, frequently voting for new leaders instead of working on what it's actually needed.
Membership and Coordination (ZooKeeper and etcd)#
Systems designed to hold small amounts of memory that can fit in memory and be efficiently replicated across all the nodes using a fault-tolerant total order broadcast algorithm.
ZooKeeper can be used for:
- Total order broadcast: and hence consensus.
- Linearizable atomic operations: Compare-and-set, for example. Can be used to implement a distributed lock.
- Total ordering of operations: By giving each operation a monotonically increasing transaction id (txid) and version number (cnumber) you can create a fencing token, associated to a lock.
- Failure detection: Clients maintain a long-lived session and send heartbeats to tell ZooKeeper that it's still alive. Once heartbeats stop, ZooKeeper can take actions such as releasing all locks held by that client.
- Change notifications: Clients can also watch values for changes, such as new clients, other client failures.
Also useful for service discovery - to find out which IP address you need to connect to in order to reach a particular service. Heartbeats come in useful, to quickly divert traffic from dead nodes. Service discovery does not necessarily require consensus, so asynchronously replicated read-only replicas are a feature of ZooKeeper and etcd that can be used here. (Usually not a big problem if a client tries to connect to a node that just died, it can just ask after a few seconds).
It's also a membership service - can be used to determine which nodes are currently active and live. Unbounded network delays make it impossible to reliably detect failures, but with consensus, all the nodes can agree on who's dead and alive.
Derived Data#
Systems that store and process data can be grouped into two categories:
- Systems of record: Source of truth. Normalized.
- Derived data systems: Result of taking existing data from another system and transforming or processing it in some way. If lost, can be recreated from the original source. Redundant. Denormalized values, indexes, materialized views…
Batch Processing#
Takes a large amount of input data, runs a job to process it and produces some output data. Jobs often take a while. Size of the input data usually known before starting. Throughput is all that matters.
Unix#
The Unix way of batch processing - pipes can be used to pass data from one program to the next, forming a pipeline that processes some input and produces some output. Can be very fast, since the input is processed in small chunks and each chunk is sent to the next producer as soon as it's ready, even before the previous producer processed all the input. Each program does one thing well, in Unix philosophy all programs have this I/O chaining capability. This requires a uniform interface that all programs know how to read and write to, which is a file descriptor. Programs simply read and write to stdin and stdout, any redirections to other file descriptors are up to the user.
MapReduce and Distributed Filesystems#
MapReduce is a bit like Unix tools, but distributed.
While Unix uses stdin and stdout as input and output, MapReduce use HDFS (Hadoop Distributed File System).
HDFS consists of a daemon running on each machine exposing a network service that allows other nodes to access files stored on that machine. Using techniques similar to RAID, data can be replicated to improve fault-tolerance.
MapReduce consists of the following steps:
- Read a set of input files and break it up into individual records.
- Call the mapper function to extract a key and value from each input record.
- Sort all the key-value pairs by key.
- Call the reducer function to iterate over the sorted key-value pairs. If there are multiple occurrences of the same key, they will be adjacent due to the sorting, so easy and cheap to combine in memory.
Steps 2 and 4 are where the custom data processing code lies.
- Mapper: Called once per input record, extracts a key and value from each input record. It may generate any number of key-value pairs for each record. Does not keep state between records.
- Reducer: Reducer consumes sorted key-value pairs and produces some output. State can be maintained between key-value pairs since they can be aggregated.
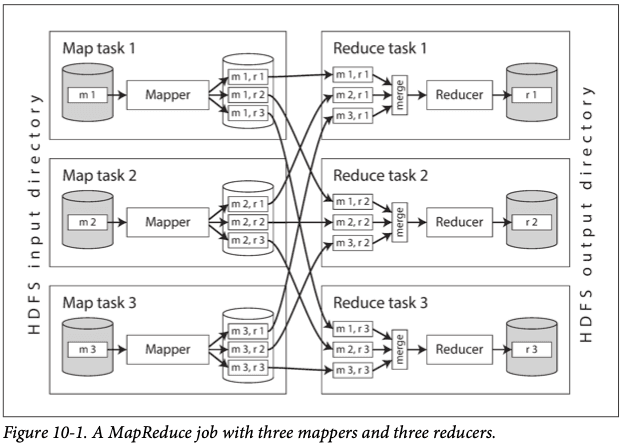
The step of partitioning by reducer, sorting and copying data partitions from mappers to reducers is known as shuffle.
It's common to chain multiple MapReduce jobs. Due to the sorting and aggregation processes, one MapReduce job can only start after the previous one ended, and this is a big disadvantage of the framework. It's also unfortunate that, in case of a skew where a lot of data ends up in one reducer, the entire process is only finished after all reducers are done.
Batch Processing Joins#
Why are they needed?
An analytics task may need to correlate user activity with user profile information: for example, if the profile contains the user's age or date of birth, the system could determine which pages are most popular with which age groups. However, the activity events contain only the user ID, not the full user profile information. Embedding that profile information in every single activity event would most likely be too wasteful. Therefore, the activity events need to be joined with the user profile database.
Note that in the algorithms described below, the only purpose of the MapReduce job is to perform the join itself.
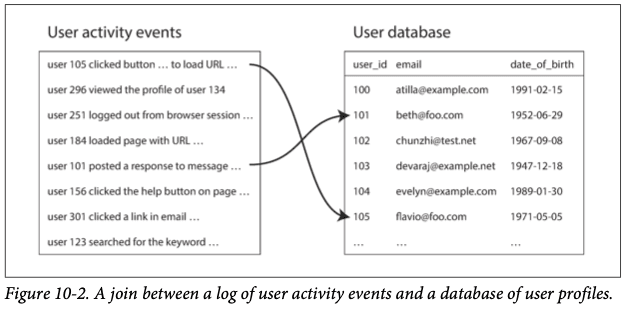
Reduce-Side Joins and Grouping#
No assumptions needed about the input data - whatever its properties and structure, the mappers can prepare the data to be ready for joining on the reducers. Can be expensive due to the partitioning, sorting and merging of all the data being joined.
Sort-merge joins
In the previous example, use the User ID as a key in the mappers and put the relevant partition of the User table on each reducer. GROUP BYs can also be performed in a similar fashion.
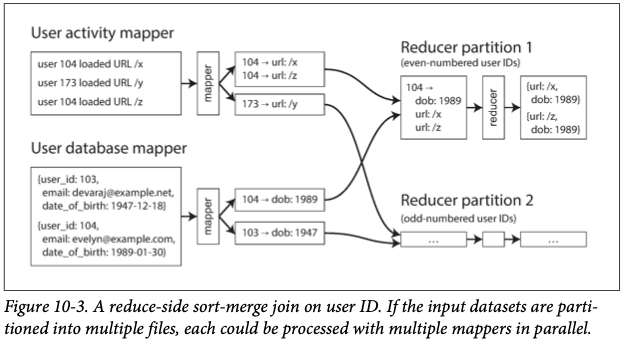
Map-Side Joins#
Can be more efficient since it doesn't require partitioning but the inputs need to have some special properties. Input and output formats must be carefully considered for the optimum strategy to be chosen.
Broadcast hash joins - Applicable when a large dataset is joined with a small dataset. The small dataset must fit into the memory of each of the mappers. Following the previous example, each mapper would enrich each record with the relevant information for each user.
Partitioned hash joins - Applicable when the inputs of the map-side join are partitioned in the same way. In this case, each mapper gets a single partition of both inputs, making it easier to fit one of them into memory, like in the broadcast hash join.
Map-side merge joins - Applicable when the inputs are not only partitioned in the same way but also sorted on the same key. In this case, none of the inputs has the requirement to fit into memory, as they can be zipped together.
Materialization of Intermediate State#
Each MapReduce job is independent from every other job. If you're chaining multiple, the output of most jobs will simply be an intermediate state - used as input for another job, useless otherwise. This contrasts to the streaming that Unix pipes perform and has some disadvantages - a job can only start after all preceding jobs are done, mappers can often be redundant as they could be part of the previous reducer, and the intermediate state has to be stored in the HDFS which can be expensive.
Dataflow engines for distributed batch computing such as Spark, Tez and Flink handle this problem by handling the entire workflow as one job. They take the operations that must be performed and do them in a flow, often deciding in an execution engine, on behalf of the user, which type of join / grouping to perform.
Stream Processing#
Like a batch processing system, consumes inputs and produces outputs rather than responding to requests. However, a stream job operates on events shortly after they happen, whereas a batch job operates on a fixed set of input data. Size of the input data may not be known (it may even never end).
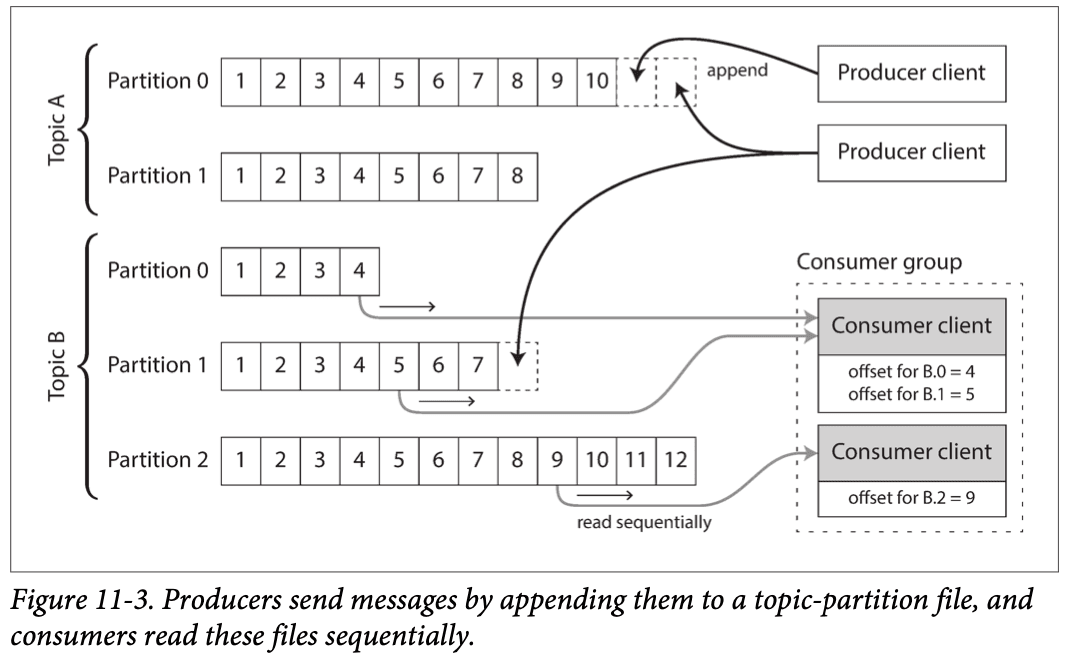
In stream processing, a record is commonly an event, and is usually timestamped. Producers are publishers, or senders, and consumers are subscribers or recipients. Related events are usually grouped into a topic or stream.
Messaging Systems#
HTTP / RPC: Messages can get lost, assumes that producers and consumers are constantly online.
Message brokers: Database optimized for handling message streams. May persist messages in disk so that they are not lost. When consumers are slower than producers, the support queueing (bounded or unbounded.
Two types of operation: Load balancing, where only one consumer gets each message, or fan-out, where each message is delivered to all consumers. These two patterns are not mutually exclusive and can be combined.
In AMQP/JMS-style messaging, receiving a message is destructive - message is deleted from the broker when received, so you cannot run the same consumer again and expect the same result. This style is useful in situations where messages may be expensive to process and you want to parallelize processing on a message-by-message basis, and message ordering is not important.
Alternatively, message brokers can use a log-based storage engine to store messages. This gives them the durability benefits of log-based databases. Each consumer stores its offset and can resume reading from a particular message onwards. There is the option of running a consumer from scratch if needed. Disk space and buffering for slow consumers are problems that need to be considered. If consumers are deterministic (as they should preferably be), consumers can be replayed and the same output should be produced.
Databases and Streams#
Often there is a need to keep in sync heterogeneous storage systems (for example, a PostgreSQL db and an ElasticSearch cluster). Using stream-like solutions we can create a simple system where all these storage systems easily become eventually consistent.
Databases often have replication logs, to replicate data to read-only records. Some allow third-party access to these logs, through a mechanism called Change Data Capture.
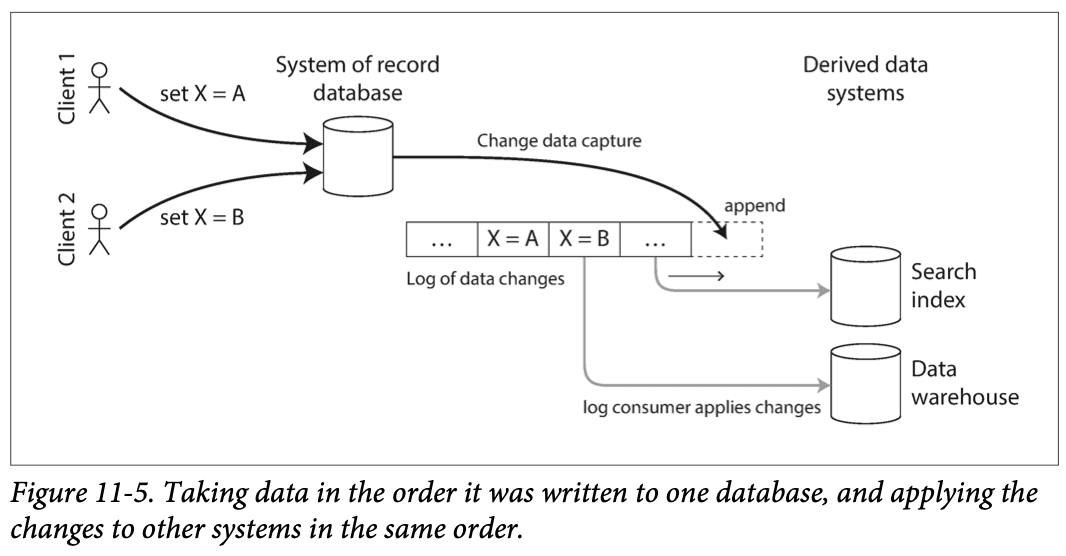
This is better than using triggers or unreliable listeners for propagating changes. Has the downside of being only eventually consistent (has replication lag problems).
To start the process, you'll need an initial snapshot of the system of record. This initial snapshot should also contain a reference point so that you know from which point of the CDC replication log you need to resume.
Alternatively, you can also use log compaction to make sure that the log always has all the most recent database entries, so a new consumer only needs to read from the offset 0 of the CDC replication log and is guaranteed to get all the most recent data changes.
Important tools in this area: Firebase, CouchDB, Meteor (MongoDB), VoltDB, Kafka Connect.
This is similar to the concept of event sourcing: In event sourcing, the application logic is explicitly built on the basis of immutable events that are written to an event log. In this case, the event store is append-only, and updates or deletes are discouraged or prohibited. Events are designed to reflect things that happened at the application level, rather than low-level state changes.
You can also search on a stream - the system stores a search query, continuously performs that query with coming events, when it finds an event that matches does something. This is Elasticsearch percolator feature. This is sort of an inversion of control - typically systems persists data and a search query is ephemeral, here data is ephemeral and the search query is persisted.
Time in Stream Systems#
Event time may be very different from processing time. If you have systems where you want to measure the average of requests over a time range, like the last 5 minutes, there may be inconsistencies and unrepeatable queries due to delayed events.
You can ignore the straggler events and drop them, or publish a correction, an updated value for the window.
To avoid clock sync issues, you can have three timestamps on the event:
- The time at which the event occurred, according to the device clock.
- The time at which the event was sent to the server, according to the device clock.
- The time at which the event was received by the server, according to the server clock.
By subtracting the second timestamp from the third, you can estimate the offset between the device clock and the server clock. You can then apply that offset to the event timestamp, and thus estimate the true time at which the event actually occurred.
You can apply several types of windows:
Tumbling window: Fixed length, every event belongs to exactly one window. [10:00, 10:05], [10:05, 10:10], etc.
Hopping window: Fixed length, with some overlap between two windows.[10:00, 10:06], [10:04, 10:10], etc.
Sliding window: Fixed length, includes all events that occur within some interval of each other. For example, last 5 minutes. Can be implemented by keeping a buffer of events sorted by time and removing old events when they expire from the window.
Session window: No fixed duration, groups together all events for the same user session, starts when user session starts and ends when user session ends.
Stream Joins#
Stream-stream join (window join): Both input streams consist of activity events, and the join operator searches for related events that occur within some window of time. For example, it may match two actions taken by the same user within 30 minutes of each other. The two join inputs may in fact be the same stream (a self-join) if you want to find related events within that one stream.
Stream-table join (stream enrichment): One input stream consists of activity events, while the other is a database change‐log. The changelog keeps a local copy of the database up to date. For each activity event, the join operator queries the database and outputs an enriched activity event.
Table-table join (materialized view maintenance): Both input streams are database changelogs. In this case, every change on one side is joined with the latest state of the other side. The result is a stream of changes to the materialized view of the join between the two tables.
All join types require some state to be maintained. The order of the events is important (for example, if you first followed and then unfollowed, the order matters). If the stream processing is distributed or parallel that means that the process may not be deterministic. This may or may not be fine given the circumstances.
Fault Tolerance#
What happens when stream processing fails? You can break the stream into small batches and checkpoint between each batch. Implicitly provides a tumbling window, but other windows can be implemented if data passes from one batch to the next.
If there is a fault, events may be processed twice. To ensure exactly-once semantics, you can have a distributed transaction or idempotence.